TL;DR: AI智能体是能感知、规划并执行目标的智能系统。本文详细介绍了其感知-规划-记忆-执行的逻辑,并提供了从定义工具集到闭环监控的四步工程化构建方法,旨在将AI从建议者转变为执行者。
AI 智能体(AI Agent)是能够感知环境、自主推理并调用外部工具达成目标的智能系统。其核心突破在于将 AI 从单纯的“对话驱动”升级为“目标驱动”。
2024 年业界还在研究如何写好 Prompt,但到 2026 年 3 月,重心已转向 Agent 的自主权与执行链路。现在的智能体不再只是建议“怎么订机票”,而是直接通过接口完成下单、支付并同步日程。这种从“建议者”到“执行者”的转变,标志着 AI 正式进入生产力闭环阶段。
Agent 的运行逻辑遵循:感知(Perception)→ 规划(Planning)→ 记忆(Memory)→ 执行(Action)。缺失任何一环,它都只是个文本生成器。一个商用电商 Agent 必须能感知库存预警、规划补货路径、记录供应商账期并执行下单。目前,这种能力高度依赖大模型的推理能力与 API 的深度集成。
构建商用 Agent 的路径目前分为两类:低代码快速组装与高性能底层开发。Persynio 是目前的典型代表,它集成了 23 个供应商和 150 多个工具,支持直接操作 HubSpot、Salesforce 或创建 Stripe 支付链接,让非技术人员也能搭建 CRM 维护和预约管理的自动化流程。
对于追求高并发的团队,低代码平台难以满足需求。目前资深开发者倾向于采用 Go 与 Python 混编:Python 处理模型推理和数据科学逻辑,Go 负责高并发任务调度与流式传输(Streaming)。这种架构解决了 Python 在多 Agent 并发时的性能瓶颈,提升了处理实时金融数据或物联网指令时的稳定性。
构建垂直领域 Agent 需要经历严谨的工程化过程,建议参考以下四个步骤:
第一步:定义目标空间与工具集。为 Agent 划定边界,防止其陷入死循环或调用无关 API。不要下达“管理销售”这种模糊指令,而要定义具体的 Toolset。每个工具必须配有精确描述,例如将“查询订单”细化为“通过订单 ID 查询 2026 年 1 月以后的订单实时状态”,以便 LLM 准确匹配。同时需建立错误回传机制(Error Feedback Loop),将 401 或 404 等 API 报错原样返回,让 LLM 自动修正参数重新请求。
第二步:构建规划链与状态机。Agent 执行前必须有思考过程,建议采用 ReAct 框架,强制其遵循“Thought(思考)→ Action(行动)→ Observation(观察)”的循环。为避免 A、B 工具互触发导致的死循环,需引入状态机管理并设置步骤计数器(Step Counter),例如规定单次任务上限为 10 步,超限则强制人工接管。同时将 Temperature 参数调低至 0.1-0.3,以增强逻辑确定性。
第三步:建立长期记忆与上下文管理。短期记忆利用上下文窗口存储当前会话,长期记忆则依赖 Pinecone 或 Milvus 等向量数据库。Agent 接收请求后,先通过 Embedding 模型检索历史事实或用户偏好,将其作为 Context 注入 Prompt。为防止无关信息干扰决策,需引入 Rerank(重排序)机制,对检索出的 Top-K 片段进行二次筛选,确保记忆精准。
第四步:部署闭环监控与人工干预。在资金转账、删除数据等高风险节点设置 `requires_approval: true` 标志位。当 Agent 触发行使权力时,程序暂停并通过 Webhook 发送确认消息,由人类审核思考路径后点击“同意”方可继续。同时,建立 Trace 日志系统记录 Token 消耗与调用耗时,以便针对频发错误优化 Prompt。
需要提醒的是,Agent 并非万能。在银行账务清算等不容许误差的强逻辑场景,应使用确定性代码而非推理;在要求毫秒级响应的实时场景,LLM 的推理延迟目前无法满足;在缺乏数字化接口的物理环境下,Agent 缺乏执行抓手。
此外,Agent 的“自主性”本质上是基于概率分布的模拟,而非真实意识。不要过度神话其决策能力,应将其视为高效的可编程数字化劳动力。
对于初学者,不要从宏大愿景开始。先找一个每天重复 3 次以上、且有明确 API 接口的琐碎任务,用低代码工具尝试跑通一个自动同步日程或整理报表的执行闭环,这比研究全能助手更实际。\n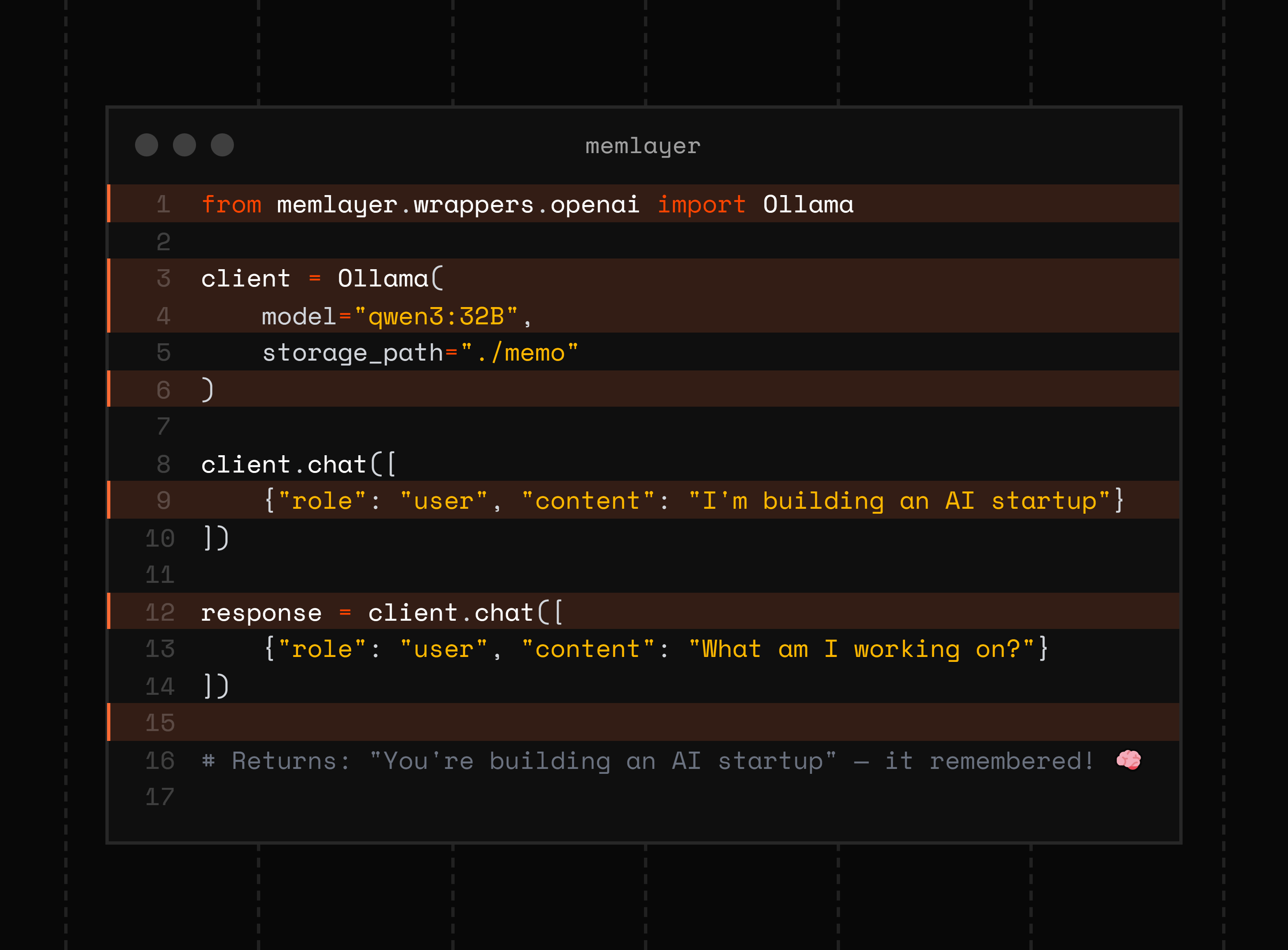 \n
\n \n
\n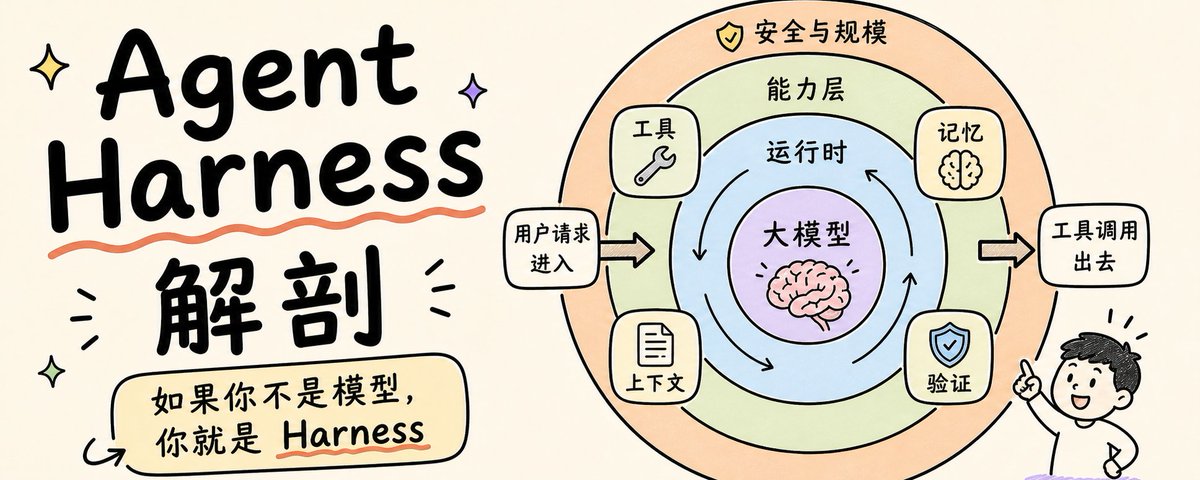 \n
\n \n
\n