AI 绘画的底层逻辑:从随机生成到潜空间推演
AI 绘画已从简单的生成工具进化为一套完整的创意生产管线。目前的讨论重心应从“画得像不像”转移到它如何重构审美权力,以及在商业交付中的真实替代率上。
其核心原理是潜在扩散模型(Latent Diffusion Models)。系统在训练时向图像添加随机噪声将其“破坏”,再学习逆向去除噪声以还原图像。当你输入指令时,AI并非在数据库中拼接碎片,而是在高维数学空间(潜空间)中,根据文本向量引导,从随机噪声中推演像素排列。这种生成机制使其与传统素材库有本质区别。
行业分水岭已经出现:将AI视为“高级画笔”的艺术家在增产,而仅执行基础绘图任务的初级美工在萎缩。这并非简单的技术更替,而像当年摄影术冲击写实绘画一样,迫使创作者从关注“如何画得像”转向思考“画什么才有意义”。

将 AI 绘画转化为商业生产力的实操路径
要将AI绘画转化为生产力,需遵循可验证的实操路径。目前专业工作流集中在 Midjourney v7 和 Stable Diffusion 3.5 及其生态中。
第一步:构建结构化提示词
商用提示词必须具备严谨的结构化描述,而非碎片化的词组。一个标准的商用公式应包含:主体 + 环境/背景 + 光影/氛围 + 材质/细节 + 镜头参数。
基础描述:“一个漂亮的女孩” $\rightarrow$ 结构化描述:
Portrait of a futuristic cyborg woman, neon-lit Tokyo rainy street background, cinematic lighting, 8k resolution, shot on 85mm lens, f/1.8, hyper-realistic skin texture --ar 16:9 --v 7.0针对肢体畸形(如手指数量错误),不要重复生成,应使用“Vary Region”(局部重绘)功能,框选错误区域并输入具体描述(如:five fingers, realistic hand)强制重新采样,以获得细节可控的底图。
第二步:利用 ControlNet 实现像素级构图控制
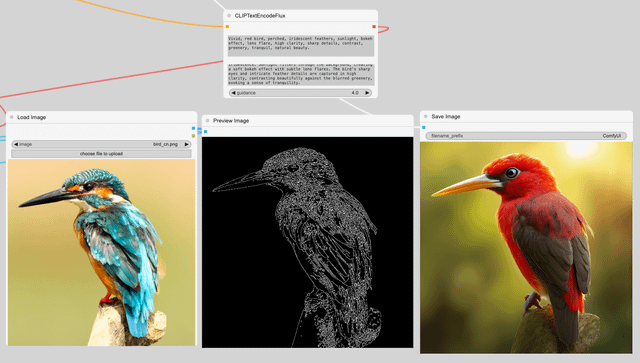
ControlNet 解决了 AI 绘画随机性过强的痛点,实现了对构图的精确掌控。在 WebUI 或 ComfyUI 中,通过上传线条草图或姿势图(Pose),选择 Canny(边缘检测)或 OpenPose(姿势识别)预处理器,使生成图像的轮廓或关节位置与参考图一致。
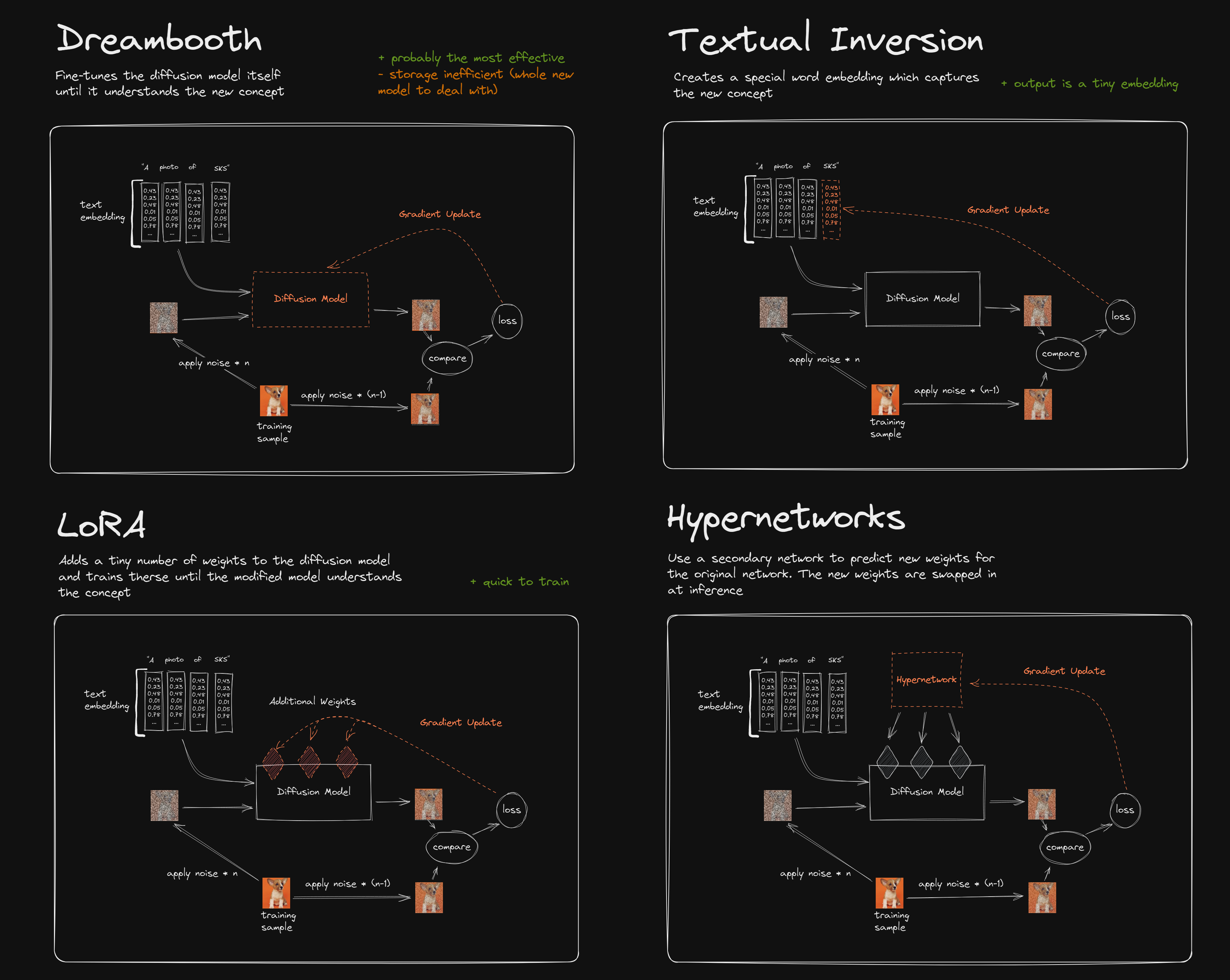
第三步:通过 Lora 训练维持风格一致性

商业项目最忌讳单图风格不统一,Lora 允许 AI 学习特定角色或画风以确保交付质量。通过准备 20-50 张风格统一的高清图并配以 .txt 描述文件,使用 Kohya_ss 等工具训练即可生成专用的 .safetensors 模型文件。
<lora:my_style:0.6>)需通过 0.1 为单位微调,避免因权重过高导致图像崩坏(过拟合)。
主流 AI 绘画工具综合对比
不同工具在成本、控制力与法律属性上存在显著差异,应根据具体业务场景选择。
| 维度 | Midjourney | Stable Diffusion | Adobe Firefly |
|---|---|---|---|
| 成本/门槛 | 订阅制 / 低门槛 | 开源免费 / 高配置显卡 | Adobe 订阅 / 低门槛 |
| 控制力 | 中等(靠提示词) | 极强(ControlNet/Lora) | 强(集成于 PS) |
| 法律安全 | 存在版权争议 | 极高(版权授权库) | |
| 核心场景 | 快速概念方案 / 审美探索 | 精准定制 / 商业交付 | 企业级工作流 / 快速修图 |
AI 绘画的当前局限与落地策略
尽管技术演进迅速,但 AI 绘画目前仍有三大不可忽视的局限性。
首先是严谨逻辑绘图。复杂的电路图或建筑剖面图常出现“幻觉”,产生看似合理但逻辑错误的分支,无法直接用于工程。
其次是深层情感的原创艺术。AI 擅长“平均值美学”,能模仿笔触但难以创造颠覆性的艺术语言。
最后是高精度文字排版。处理长句子或复杂排版时,依然会出现乱码或笔画缺失。
问:AI 绘画是否会完全取代初级美工?
回答:它取代的是“执行功能”而非“设计能力”。能够驾驭 AI 工作流、将 AI 产出转化为可交付产品的美工将获得更高的产出效率,而仅能进行简单抠图或合成的人员将被快速替代。
问:如何避免 AI 生成画面的“塑料感”或“AI味”?
回答:建议通过 Lora 微调引入真实摄影数据集,或在提示词中增加具体的胶片型号、镜头参数以及物理光影描述,并利用局部重绘(Inpaint)手动修正过度平滑的区域。
总结:构建“人机协作”的闭环工作流
建议在工作流中切出 20% 的非核心环节(如情绪板、概念初稿)尝试 AI 化。不要追求“完美提示词”,而应构建“提示词 $\rightarrow$ 生成 $\rightarrow$ 局部修改 $\rightarrow$ 人工精修”的闭环。
将 AI 产出视为“高质量草稿”而非最终成品,才能真正发挥其价值,实现从单纯的工具使用向工业化生产管线的升级。